Untangle your Planning Analytics model string by string
Introduction
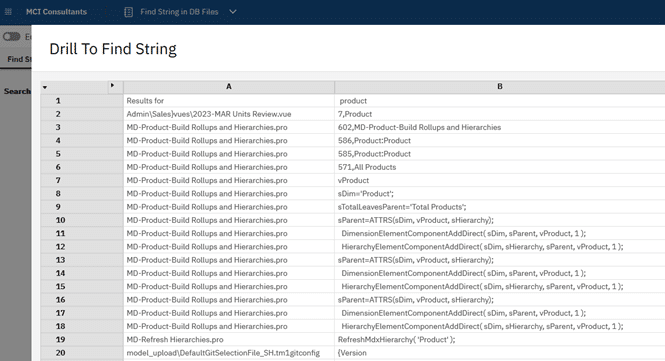
The simple example in this article will allow you to build your own quick search to recurse the data directory and find objects matching your search criteria.
There are a few components that we need to build the PAW book that will allow us to perform the search and view the returned results.
User Preferences Cube
Update the User Preferences Dimension
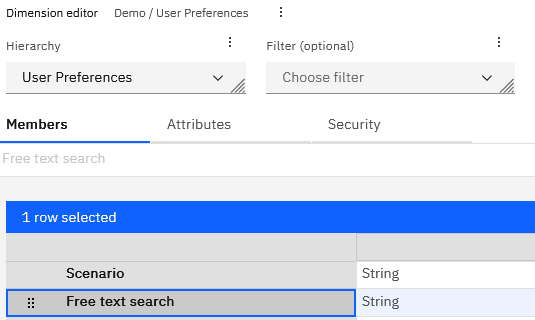
Many models already have some kind of User Preferences cube that is leveraged for user-based MDX queries as well as TI variables. We will add a new string member, Free text search, to our User Preferences dimension in the User Preferences cube:
Create the User Preferences cube
If you do not already have a User Preferences cube, you can create it simply by creating the User Preferences dimension first, adding the string member then creating a cube with the two dimensions per below:

Create a Current User set
Open the set editor on the }Clients dimension then open the MDX window and add the following:
STRTOMEMBER("[}Clients].[" + UserName + "]")
Save the set with a name like _S-Current User or your convention.
Create the PAW book
We need to create a simple PAW book to display only one cell where we expect users to enter a search string.
To replicate the above, create a new book then add a view from the User Preferences cube. Update the view to have the following:
- }Clients on the rows
- Link the }Clients set to the _S-Current User set you just created
- Select or keep only the Free text search member from the User Preferences
- Widen the column on Free text search to ensure that it accommodates enough text
- Collapse overview as we will not need this
- Open the widget properties and do the following:
- Set the border to black
- Adjust the corner radius to 5 px
- On the custom tab, turn off all options, especially column and row headers to give us what looks like a single cell. I chose not to use a single cell widget here for simplicity.
- Add the other text boxes with information needed
- I added a graphic for the magnifying glass but option
- Save the book.
Drill Through Process
Create the Drill Rules
From the database tree in a workbench, use the kebab menu next to the User Preferences cube to access Drill and then Create drill rules. We want to point to a new process to do the drill when right-clicking on the Free text search
Update the drill rules with a rule per the below:
['User Preferences':'User Preferences':'Free text search']=S:'Drill To Find String';
When we drill, PA will execute a drill process called }Drill_Drill To Find String.
Create the Drill Process
Use the kebab menu again on the User Preferences cube and this time under the Drill options, choose Create drill process.
You can paste the following into Prolog:
#=====VARIABLES=====
#--Set the filename and write to the Logs folder
sFolder = GetProcessErrorFileDirectory();
sFilename = sFolder | 'findstring.txt';
#===================
#=====RUN THE SEARCH=====
#--Run the child process to execute the search and build the file
ExecuteProcess( '_S-System-Find String in DB Files');
#========================
#=====SET DATA SOURCE=====
#--Configure the data source and use a colon as a separator to keep object/file name in column A and other details in subsequent columns
DataSourceType = 'CHARACTERDELIMITED';
DatasourceASCIIDelimiter=':';
DatasourceNameForServer=sFilename;
#=========================
You will notice from the above that we are executing a child process. The child process will perform the actual work of doing the filesystem search and creating the file.
This process will then simply render the file contents as a set of results.
We the critical function in Epilog to show the contents of the file. Paste this code into Epilog:
#=====OPEN THE FILE IN THE VIEWER=====
#--Trigger the viewer in PAW
ReturnCSVTableHandle();
#=====================================
If you scan through the code you will see that we are expecting a text file to be created in the Logs directory. We want to open this with a colon as the delimiter is the command line function returns results and <filename>:<string>. We expect to have the filename in column A and anything else in column B or subsequent columns.
Create the Child process
Create a new process called: _S-System-Find String in DB Files
You can call it something else but remember to align the name in the Drill process above.
You can paste the following into Prolog:
#=====VARIABLES=====
sFolder = GetProcessErrorFileDirectory();
sFilename = sFolder | 'findstring.txt';
#===================
#=====SEARCH STRING=====
#--Retrieve from User Preferences cube
sSearchString=CellGetS('User Preferences', TM1User(), 'Free text search' );
#=======================
#====BUILD COMMAND=====
#--Write the first line to ensure we always have a file
sCMD='CMD /C ECHO Results for: ' | sSearchString | ' >"' | sFilename | '" 2>&1 & ';
#--Append the Findstr command
#-- /I to ignore case
#-- /P to exclude binary or non-text files
#-- /S to recurse directories
#-- /C to search for a phrase i.e. our text string
sCMD=sCMD | 'FINDSTR /I /P /S /C:"' | sSearchString | '" "*.*" >>"' | sFilename | '" 2>&1';
#--Execute the command and wait until it completes
ExecuteCommand( sCMD, 1 );
#======================
The code above essentially does the following:
- Builds the filename to be written to which is aligned to the Drill process which needs to read this file
- Retrieve the string or phrase from the one entered into the User Preferences cube
- Writes a header line to the file ensuring that the file will never be blank / zero length
- Calls FindStr via the command line and executes the search with any results being written to the file
Once the child process completes, control is returned to the Drill process where the data source is set to the filename and the ReturnCSVTableHandle reads and returns the view to the user.
Testing the process
With all of the above complete, we should have the following:
- User Preferences cube with the string measure
- PAW book with the string measure
- Drill process and child process
All that remains now is to test the process.
Capturing a search string
Open the PAW book and enter a likely word or phrase into the field:
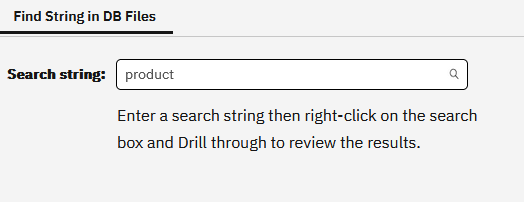
I am going to look for files containing the word “product”
Drill to search process
Right-click then click Drill through and then select Drill To Find String to execute our drill process:
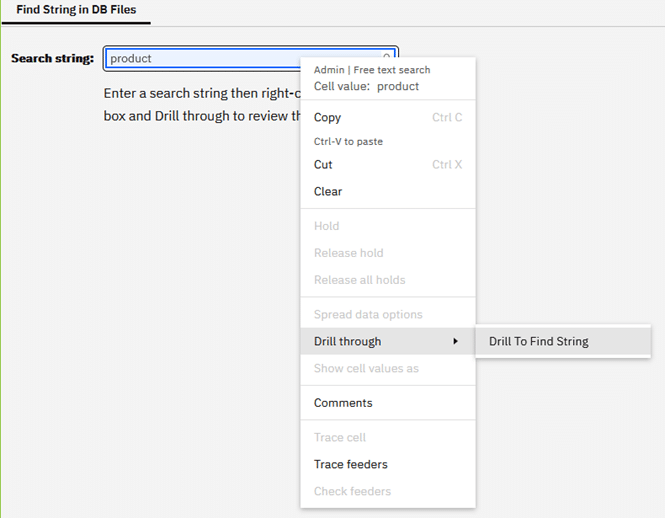
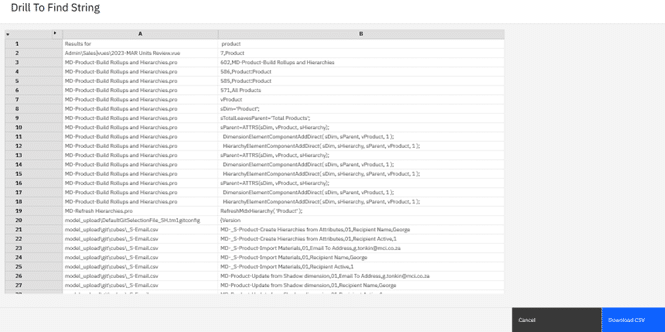
View results
The drill process will execute and depending on the size of your model in terms of number and size of files, the search will take some time then return the results in a window per below screenshot.
You can wide then columns as needed to view the filenames in column A and other detail in column B.
Where to From Here
Essentially the concept here is showing how you can use the ReturnCSVTableHandle() function to read and display text files within PAW.
I have used this concept to allow users to review non-sensitive log files as well as other text files that may be created from within Planning Analytics or from 3rd party systems. Sometimes this approach allows users to preview a set of data before importing a file, or like with the logs, review the results.
Note too that there is an option to Download CSV. This will save the file locally and allow you to open in another application e.g. Excel.
I hope this will be a very practical and useful exercise and would like to hear back on other applications you may have. Reach out to me in the comments below.
Further Reading
Part 1 – Learning MDX view in Planning Analytics
Part 2 – Using Calculated Members in MDX
Part 3 – Aggregate Calculated Members in MDX
Part 4 – Using Calculated Members to Add Information
Part 5 – Working with Attributes in MDX Views
Part 6 – Working with Time Series in MDX Views
Part 7 – Using Lookup Cubes to Extend Your Queries
Part 8 – Joining Related Cube Data
Part 9 – Joining Related Cube Data(Part 2)
TM1/Planning Analytics – MDX Reference Guide
Working with Time Related MDX Functions
Discovering MDX Intrinsic Members